Ключевые концепции
Прежде чем начать работу с aiWarmUp, полезно разобраться в основных терминах и понятиях платформы. В этой статье мы рассмотрим каждый из них.
Воронка (Pipeline)
Заголовок раздела «Воронка (Pipeline)»Воронка — это визуальный рабочий процесс, который описывает последовательность действий над данными. Она состоит из процессоров, соединённых между собой, и представляет собой граф обработки данных.
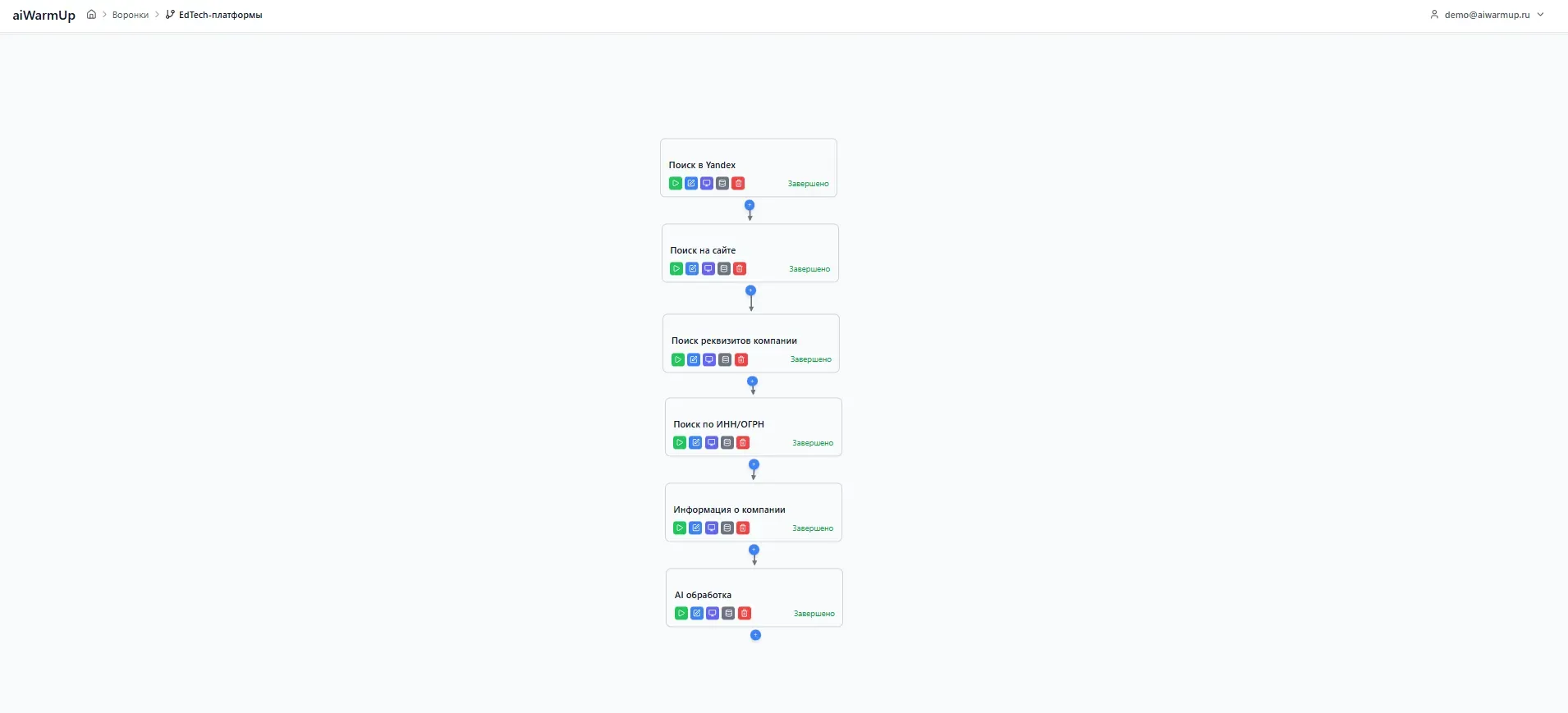
Каждый пайплайн имеет:
-
Название — для удобной идентификации среди других пайплайнов.
-
Набор процессоров — блоки, которые выполняют конкретные действия.
-
Соединения — связи между процессорами, определяющие порядок передачи данных.
-
Статус — текущее состояние воронки: черновик, запущена, завершена, остановлена или ошибка.
Воронку можно запускать многократно. Каждый запуск обрабатывает новые данные, не затрагивая результаты предыдущих запусков.
Процессор (Processor)
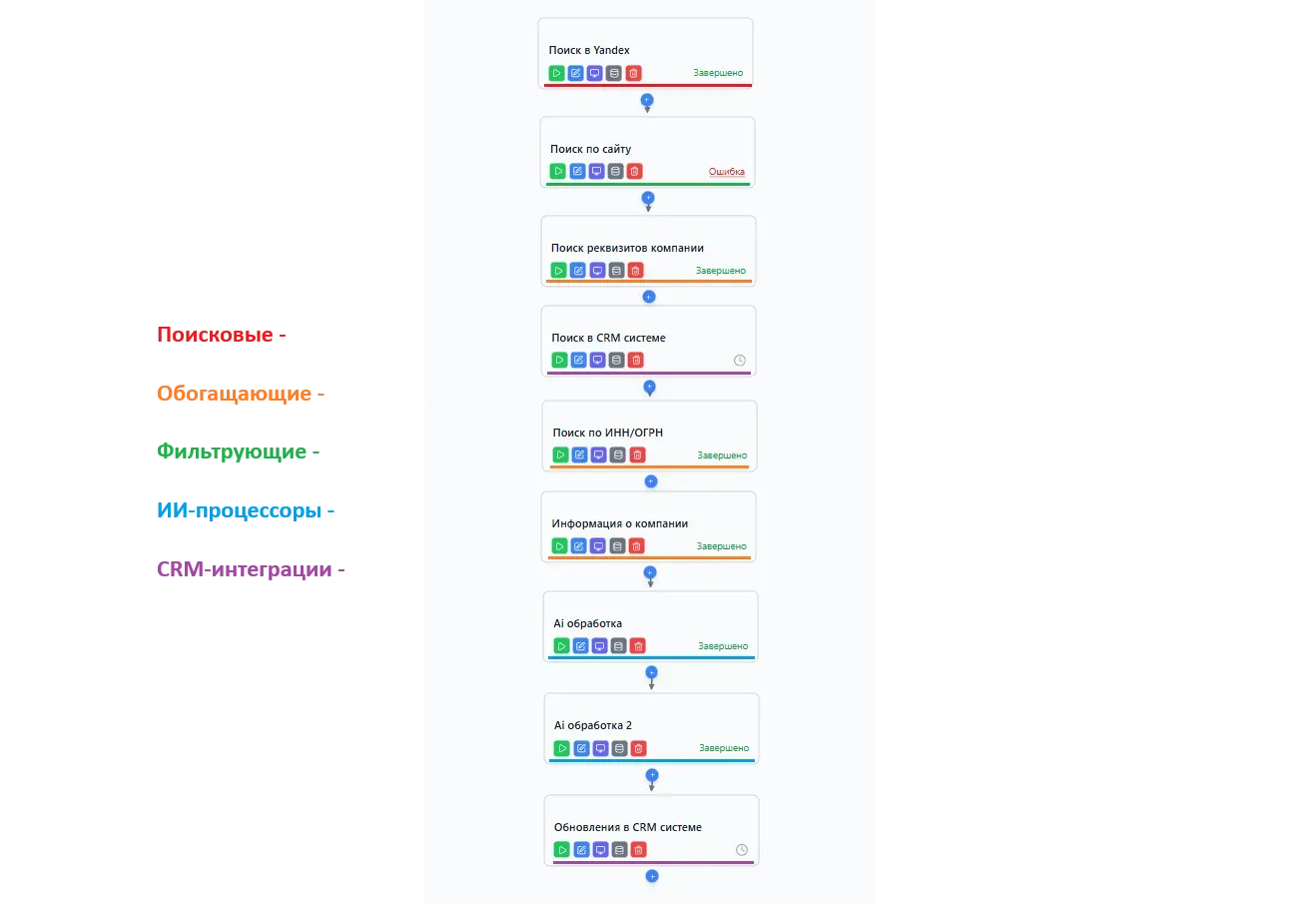
Заголовок раздела «Процессор (Processor)»Процессор — это отдельный блок в пайплайне, который выполняет одну конкретную задачу. Процессоры бывают разных типов:
- Поисковые — находят компании в различных источниках по заданным критериям.
- Обогащающие — дополняют найденные данные информацией из других источников.
- Фильтрующие — отбирают записи по заданным условиям, отсеивая нерелевантные.
- ИИ-процессоры — используют искусственный интеллект для анализа, классификации и генерации текстов.
- CRM-интеграции — передают обработанные данные во внешние системы.
DataPacket (“Пакет” данных)
Заголовок раздела «DataPacket (“Пакет” данных)»“Пакет” — это единица данных, которая проходит через пайплайн. Каждый “пакет” представляет собой одну запись: информацию об одной компании, одном контакте, одном результате поиска и т.д.
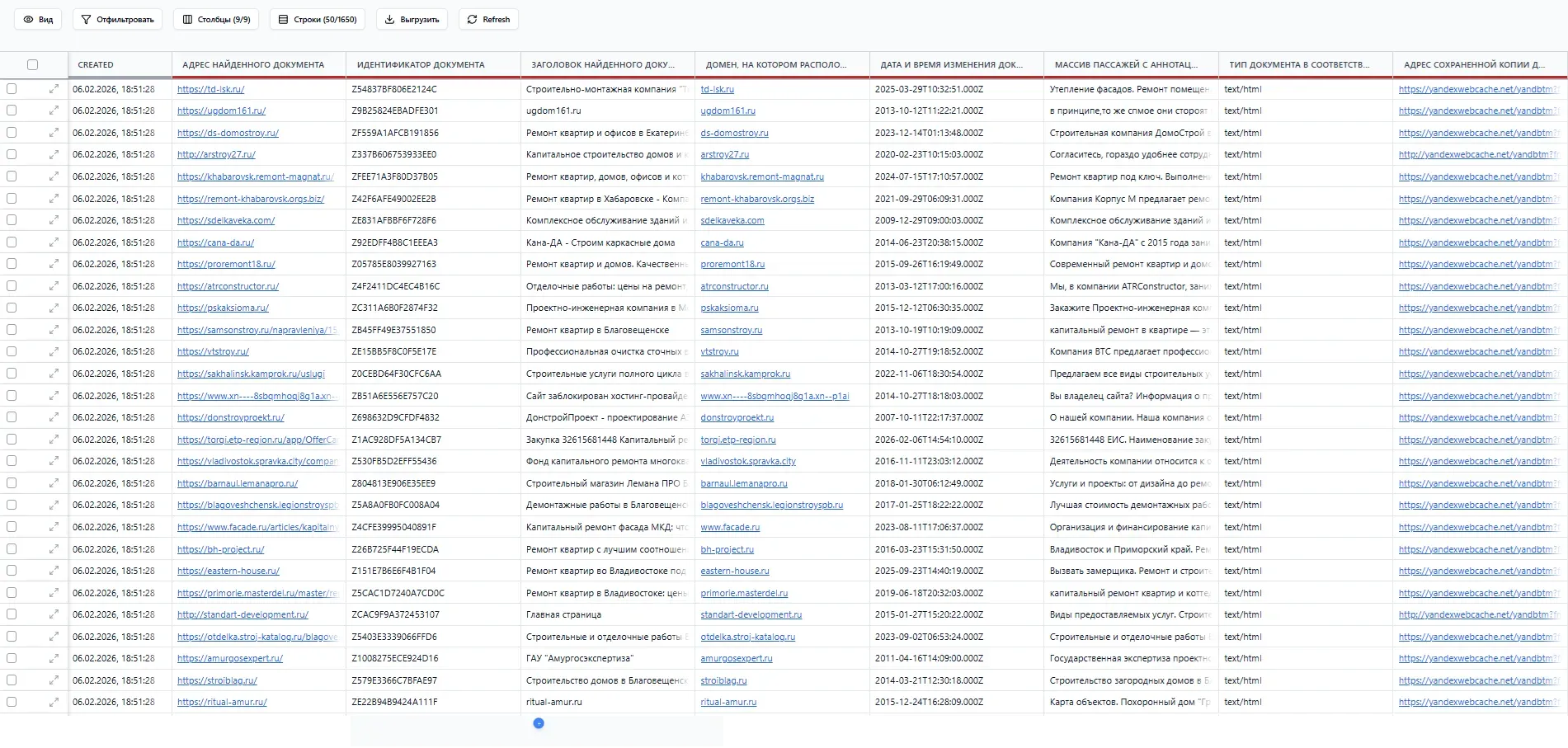 Таким образом, каждая компания является “пакетом” внутри вашей воронки
Таким образом, каждая компания является “пакетом” внутри вашей воронки
Соединение (Connection)
Заголовок раздела «Соединение (Connection)»Соединение — это связь между двумя процессорами, которая определяет направление потока данных. Когда вы соединяете процессор A с процессором B, вы указываете, что DataPackets, созданные процессором A, будут переданы на вход процессору B.
Правила соединений:
- Один процессор может иметь как один так и несколько исходящих соединений.
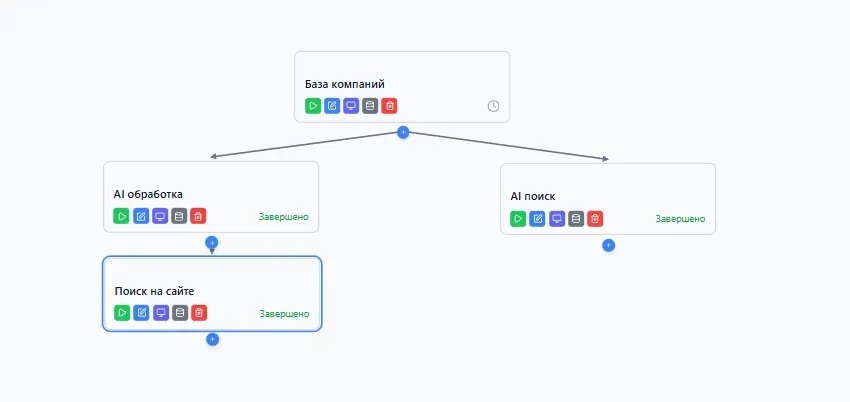
- Данные передаются строго в направлении соединения (от источника к приемнику).
- Процессор начинает обработку только тех пакетов, которые поступили от подключенных к нему источников.
- Соединения создаются перетаскиванием от выхода одного процессора ко входу другого.
Переменные (Variables)
Заголовок раздела «Переменные (Variables)»Переменные позволяют ссылаться на данные из других процессоров при настройке параметров. Это один из самых мощных механизмов платформы.
Синтаксис
Заголовок раздела «Синтаксис»Переменные записываются в двойных фигурных скобках:
{{имяПроцессора.имяПоля}}
Примеры использования
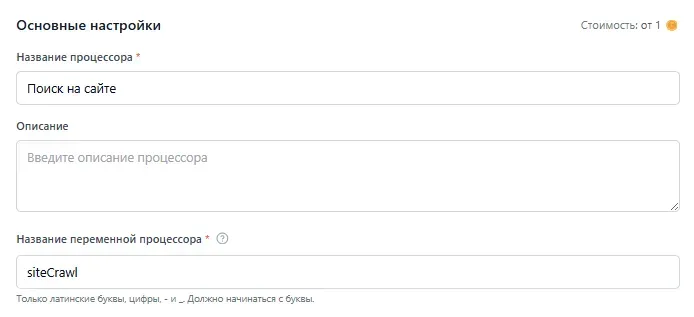
Заголовок раздела «Примеры использования»- {{siteCrawl.companyName}} — название компании из процессора “siteCrawl” (он же “Поиск на сайте”).
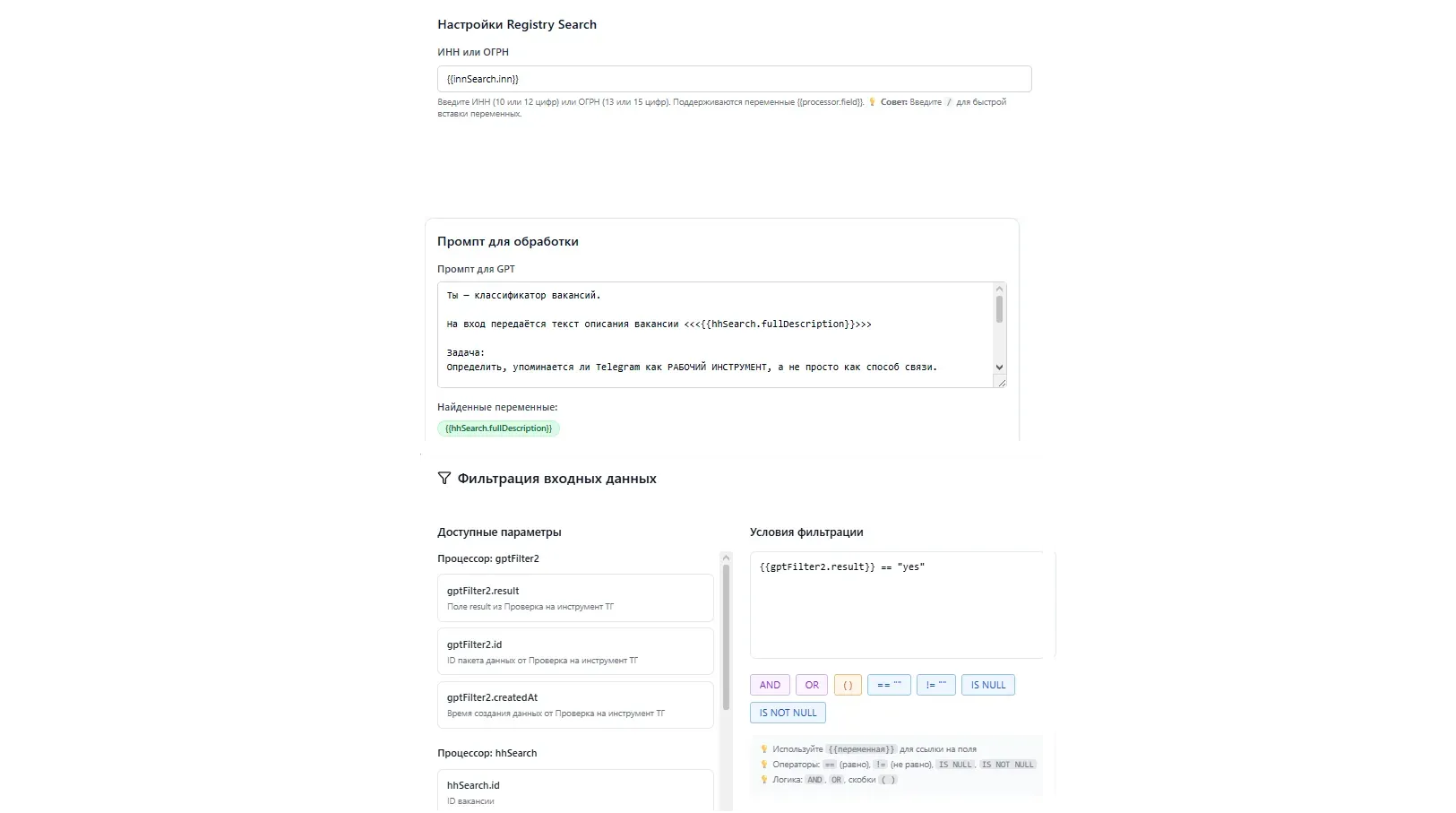
- {{innSearch.inn}} — ИНН из процессора “innSearch” (Он же “Поиск реквизитов компании”).
- {{gptFilter.email}} — email из процессора “gptFilter” (Он же “Ai обработка”).
Переменные подставляются автоматически при добавлении процессора (не нужен ручной ввод). Для каждого “пакета” значения переменных берутся из соответствующих данных в цепочке обработки.
Где можно использовать переменные
Заголовок раздела «Где можно использовать переменные»- В текстовых полях конфигурации процессоров.
- В шаблонах сообщений и промптах для ИИ-процессоров.
- В условиях фильтрации.
Токены — это внутренняя валюта платформы, которая расходуется при выполнении операций. Каждый процессор потребляет определённое количество токенов за обработку одного DataPacket/“Пакета”.
Стоимость операции зависит от:
- Типа процессора — поиск в реестре стоит иначе, чем запрос к ИИ.
- Сложности операции — простая фильтрация дешевле, чем обращение к внешнему API.
- Объема данных — обработка большого текста через ИИ стоит больше, чем короткого.
Баланс токенов отображается в панели управления. Подробнее о системе токенов читайте в разделе Токены и стоимость операций.
Как всё связано вместе
Заголовок раздела «Как всё связано вместе»Типичный процесс работы выглядит так:
- Вы создаете воронку для конкретной задачи лидогенерации.
- Добавляете процессоры нужных типов и настраиваете их параметры.
- Создаете соединения между процессорами, задавая порядок обработки.
- Используете переменные для передачи данных между процессорами.
- Запускаете воронку — она создаёт DataPackets и обрабатывает их, расходуя токены.
- Просматриваете результаты, фильтруете и экспортируете нужные данные в удобный для вас формат.
Следующие шаги
Заголовок раздела «Следующие шаги»- Первые шаги — создайте свой первый пайплайн на практике
- Обзор интерфейса — познакомьтесь с элементами интерфейса платформы